OpenText 是智能文档处理领域的领导者获取 IDC 报告摘录
想要通过云文档处理提高效率?
基于 SaaS 的云采集可在任何地方使用,从而消除人工数据输入、减少错误并提高生产率。
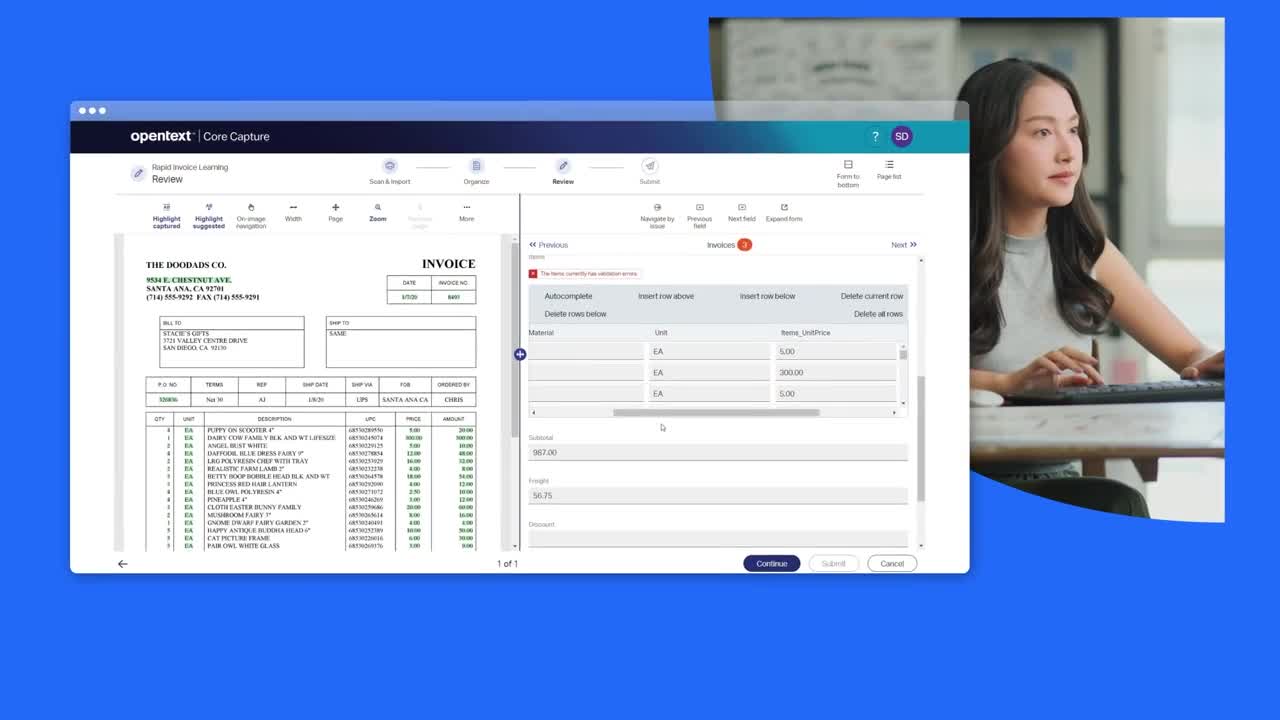
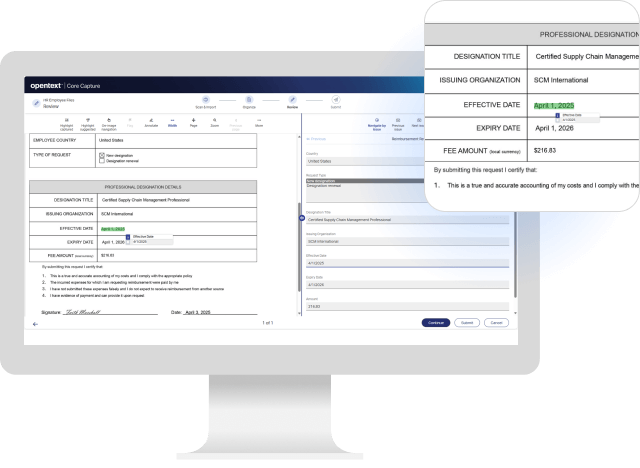
OpenText™ Core Capture 是一项 SaaS 信息采集解决方案,它使用持续机器学习和大语言模型 (LLM) 自动执行内容分类和数据提取。它结合标准采集功能——如光学字符识别 (OCR) 和强大的 AI 技术,以实现智能文档处理解决方案,并将信息安全传送到合适的用户和系统。
为什么选择 OpenText Core Capture?
通过无缝集成、全球部署和可信赖的自动化,简化工作流程,从而降低复杂性并提高效率。
- 集成
配备专为特定目的设计的 ERP 应用程序,并由紧密合作伙伴提供支持
通过与 SAP® 解决方案的深度集成,自动执行重复性的会计、销售和服务任务,而不会增加 IT 资源的负担。
探索我们的战略合作伙伴 - 全球覆盖
为国际组织提供灵活的部署方案
利用北美、欧洲和亚太地区的数据驻留选项,扩展采集操作并满足合规监管要求。 - 一家供应商
为 IDP 提供端到端文档管理和自动化的捕获功能
通过集成流程自动化、内容服务和分析,扩展捕获范围,降低复杂性并简化工作流程。
了解 OpenText™ Content Cloud

通过 OpenText™ Core Content Management 和 OpenText Core Capture,ScottsMiracle-Gro 可利用 AI 来汇总文档、整理报告并提取数据,从而确保我们的员工能够将更多的时间投入于创新。
阅读客户撰写的博客
用例
通过自动执行和优化文档流程,提高业务职能的效率、准确性和合规性——涵盖发票处理、员工入职和客户入驻、索赔处理、客户服务和审计就绪等各个环节。
-
通过自动化采购到付款流程来节省时间,并专注于高价值任务。您可以从电子邮件、扫描、传真等多种渠道轻松提取和验证发票数据,而无需依赖缓慢、容易出错的人工发票处理流程。
探索从采购到付款的流程自动化 -
简化新员工入职流程,使其更高效且更友好。利用云文档处理分析和分类文件,实现快速搜索和自动化人力资源任务和工作流。
了解人力资源自动化 -
利用智能文档处理解决方案,自动进行数据采集和验证,以了解您的客户 (KYC) 和客户入职。通过自动捕获、分类和提取数据,实现自动化的 CRM 工作流,从而节省销售代表的时间。
了解如何优化客户入职流程 -
从索赔表单和文档中自动采集可操作的数据,以提升索赔处理效率。云文档处理有助于降低成本,同时留住客户和员工,以提高整体效率和满意度。
了解如何加快索赔处理速度 -
减少缓慢、容易出错的人工工作流程,处理大量文件,改善客户服务和支持。通过云捕获和智能文档处理实现自动化,以可操作的数据增强客户互动。
了解如何提升客户服务 -
借助信息采集解决方案对文件进行自动分类,并将其转换为可检索文本的文档,以便于查找和归档,从而有效支持监管合规计划。
确保合规性并简化报告
关键功能
集中云采集,启用智能文档处理,并支持多语言操作。通过自动化升级、人工验证以及安全数据处理,您可以优化性能并减少人工工作量。

多租户 SaaS
通过完全维护的 OpenText 公有云,消除复杂的安装流程和破坏性更新,并借助简化部署和自动升级减轻 IT 人员的工作负担。


人机协作验证
通过网络用户界面提高准确性并简化维护,该界面可接入持续学习引擎,同时通过优化的工作流程和用户友好的界面提高生产力。

多模式摄取
从纸质文件、电子邮件、PDF、Microsoft® 文件和图像中自动提取信息,跨部门和位置统一采集数据,以支持可扩展的内容管理和共享服务。

智能文档分类
通过文本和图形方法识别文档,自动提高准确性和性能。

智能数据提取和验证
通过内置的 OCR、机器学习以及第三方 LLM 和识别集成功能,减少手动数据输入并确保 85 种语言和方言的准确性。

可配置的捕获工作流程
允许用户设计符合业务需求的工作流。无论是增设审核员还是支持后台处理,您都可以使用简易无代码建模器来创建工作流模板。

多种导出选项
与多个应用程序共享数据——如 OpenText™ Core Content Management、OpenText™ Content Management、OpenText™ Documentum™ Content Management 和 OpenText™ Capture——以及 CMIS 解决方案。
加速发掘 OpenText Core Capture 的价值
Add-ons
使用这些功能强大的附加组件,让您的 OpenText Core Capture 投资发挥最大效益。
-
OpenText™ Core Capture for SAP® Solutions
这一 SaaS 信息采集解决方案使 OpenText™ Vendor Invoice Management for SAP® Solutions 能够通过对内容进行分类并提取发布和路由异常所需的所有详细信息,从而在 SAP 中实现订单到现金和采购到支付流程的自动化,并将异常情况路由到 SAP 中正确的工作流程和用户
部署
探索适用于各类跨国组织、可扩展且灵活的部署方案。
-
开发、连接和扩展您的信息管理能力
OpenText™ Developer Cloud 的 API
服务
在认证专家的指导下,加速实现数字化转型。
-
通过认证专家实现信息管理现代化
专业服务
-
将支持转化为您的战略优势
支持服务
-
通过专家指导、托管服务等实现业务目标
客户成功服务
-
通过专业的 IT 服务管理解放您的内部团队
托管服务
合作伙伴
OpenText 帮助客户找到合适的方案、恰当的支持与理想的结果。
企业应用程序合作伙伴
我们与领先的企业应用程序提供商建立合作伙伴关系,助您充分释放企业信息的全部潜力。
全球系统集成商 (GSI)
这些 GSI 均已接受 OpenText 解决方案相关培训和认证,所提供的服务能够提升独立解决方案的价值。
培训
OpenText 学习服务提供全面的赋能和学习项目,加速提升知识和技能水平。
-
3-8210 – OpenText Core Capture 业务管理
本课程提供了实施和管理的基础,包括深入的知识和应用程序的使用。其中包括产品概述、工艺规范和设计;系统与租户管理;用户管理;批量处理;以及报告和监控。
社区
探索我们的 OpenText 社区。与个人和企业建立联系,获取洞察和支持。参与讨论。
-
面向使用 OpenText Core Capture 的员工、客户和合作伙伴社区提供的开放讨论论坛,供其提问和分享专业知识
OpenText™ Core Capture
-
开放的讨论论坛,供用户和管理员提问和分享经验
OpenText Core Capture SAP 解决方案
高级支持
通过专门的专家团队,为您的复杂 IT 环境提供关键任务支持,优化 OpenText 解决方案的价值。
-
获得技术和战略专家提供的个性化一对一协助
高级支持
OpenText Core Capture resources
OpenText Core Capture
Read the product overviewIntelligent document processing
Read the solution overviewContinuous machine learning: Your AI edge
Read the white paperOpenText Cloud Platform (OCP) fundamentals
Read the white paper3 ways to elevate cloud content management
Learn moreIntelligent document processing
Read the solution overviewContinuous machine learning: Your AI edge
Read the white paperOpenText Cloud Platform (OCP) fundamentals
Read the white paper3 ways to elevate cloud content management
Learn moreTransform paper and digital content into actionable data with OpenText Core Capture
Watch the video
ScottsMiracle-Gro saved costs and improved compliance with OpenText
Watch the videoCapture and intelligently file HR documentation for easy onboarding
Watch the demoCapture a batch of documents and then export to OpenText Core Content for further collaboration
Watch the demoOpenText Core Capture and intelligent document processing
Watch the demoCapture a batch of documents and then export to OpenText Core Content for further collaboration
Watch the demoOpenText Core Capture and intelligent document processing
Watch the demoBoost efficiency with SaaS: Future-proof operations with AI-powered cloud content management
Watch the webinarOpenText Content Cloud Virtual Summit 2025
Watch the webinarOpenText Content Cloud Virtual Summit 2025
Watch the webinar-
Cloud capture is the use of cloud-native technology to ingest, classify, and extract data from documents and digital content at scale. As a core component of cloud document processing, it enables organizations to capture content from scanners, email, desktops, and mobile devices while applying AI-based classification and metadata extraction. Cloud capture improves access, resilience, and speed while reducing infrastructure overhead and supporting modern information capture solutions. This enhances efficiency and accessibility by allowing users to process, review, and validate content from anywhere.
Learn more in the OpenText Core Capture product overview.
-
Cloud document processing automates time consuming capture tasks such as document sorting, classification, and data entry. By reducing manual handling and errors, organizations process documents faster and with greater accuracy. The resulting classified content, with actionable metadata, flows easily into business applications, enabling broader intelligent document processing solutions and more efficient end to end workflows.
Discover what intelligent document processing is—and how it relates to cloud data capture.
-
Yes. To help deliver intelligent document processing, OpenText Core Capture seamlessly integrates with ERPs and line-of-business applications, such as SAP® software, to streamline workflows and enhance productivity. These integrations ensure documents and captured data flow directly into business systems without manual handoffs—reducing data entry, improving consistency, and enabling faster, more reliable business processes.
Learn how OpenText Core Capture integrates with SAP® solutions.
-
AI enhances cloud capture by using continuous machine learning, natural language processing, natural language understanding, and large language models (LLM) to automatically classify, extract, and analyze data from content. This improves accuracy and efficiency, allowing organizations to process large volumes of files quickly and reliably. AI-driven capture reduces manual review and exceptions, helping teams scale operations without increasing staff or slowing down the business.
-
Cloud capture processes a wide range of content, including scanned paper, PDFs, emails, office documents, and mobile images. Intelligent document capture applies AI to normalize formats, extract text, and classify documents consistently. This ensures all inbound content is captured the same way, giving organizations a complete and reliable view of their information from the start.
Explore how cloud capture supports intelligent document workflows.
-
Cloud capture enables users to submit and process documents securely from anywhere using browser-based access. By removing dependence on on premises systems, cloud document processing ensures consistent capture quality regardless of location. This helps organizations maintain productivity, service levels, and business continuity across distributed teams.
Review the benefits of cloud-based capture in the OpenText Core Capture product overview.
-
Cloud capture is the first step in automation, converting documents into structured, trustworthy data. Accurate intelligent document capture reduces exceptions and rework downstream, enabling faster approvals and more predictable outcomes. This makes capture a critical foundation for intelligent document processing solutions and scalable business automation.
Discover how cloud capture accelerates OpenText intelligent processing solutions.

OpenText named a Leader in IDC MarketScape for Intelligent Document Processing
Learn why IDC named OpenText a Leader and download the report excerpt.
Read the blogThe new IDP for HR: A springboard for transformation
Discover how to unlock operational efficiency for employee onboarding and more.
Read the blog
What’s new in OpenText Core Capture
See product release highlights for SaaS information capture apps, including SAP and Salesforce.
Read the blog
Supercharge claims processing with an AI content assistant and IDP
See how you can help insurance adjusters resolve claims quickly and improve customer satisfaction.
Read the blog
Elevate customer service with intelligent document processing
Learn how to transform how your organization handles customer interactions and manages information.
Read the blogTransform customer onboarding with intelligent document processing solutions
See why financial institutions need to make processes faster and more accurate.
Read the blog
The ScottsMiracle-Gro Company realizes cost savings by switching to SaaS
See how they streamlined document management with cloud capture and content management.
Read the blog
Streamline procure-to-pay with intelligent document processing solutions
Harness the power of AI to enhance efficiency, reduce errors, and improve supplier relationships.
Read the blog
Ultimate guide to intelligent document processing use cases
Learn how to transform your operations with intelligent document processing solutions use cases.
Read the blog
OpenText named a leader in the 2024 Infosource Global Capture and IDP Vendor Matrix
Learn why Infosource ranked OpenText as a Star for the seventh consecutive year.
Read the blog
Continuous machine learning: Keep up with the digital document deluge
See why organizations are using CML for content classification and data extraction to enable IDP.
Read the blog