OpenText Core Capture
インテリジェントなコンテンツキャプチャでクラウドドキュメント処理を自動化
OpenTextはインテリジェントドキュメント処理のリーダーです IDCレポートの抜粋を入手
クラウドドキュメント処理の効率を高めたいですか?
どこからでも利用可能なSaaSベースのクラウドキャプチャを使用して、手動データ入力を排除し、エラーを減らし、生産性を向上させます。
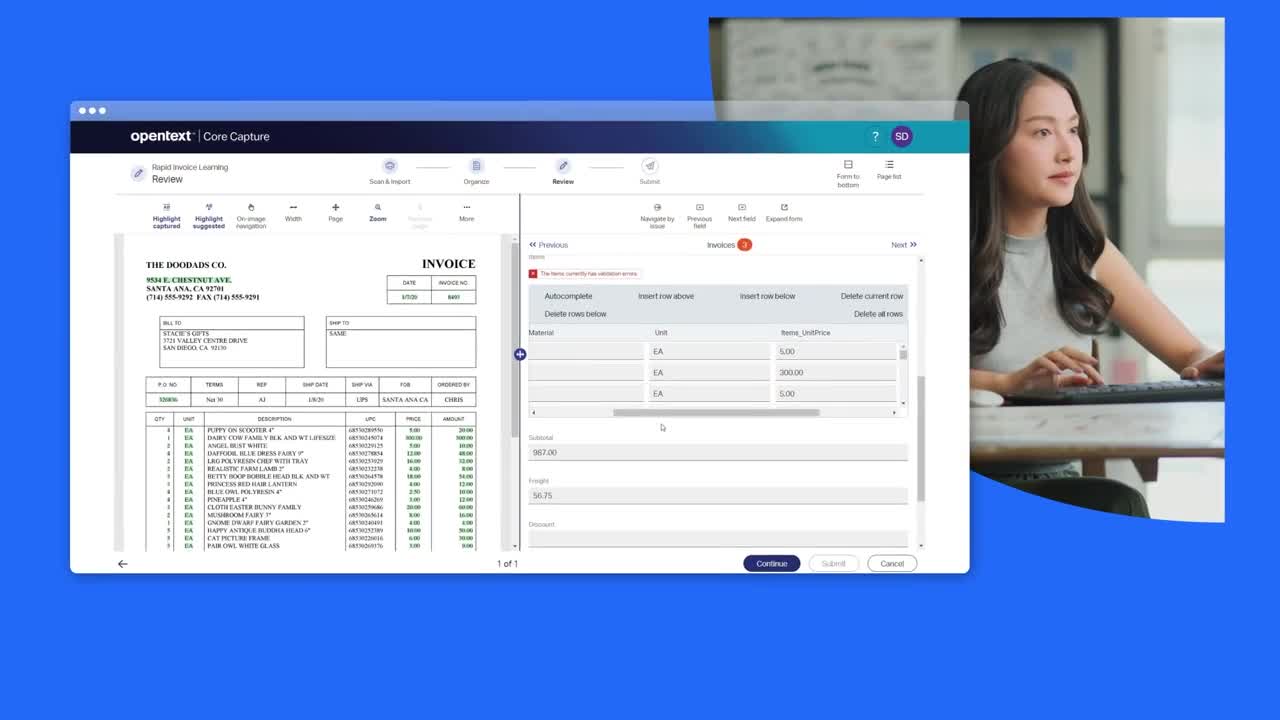
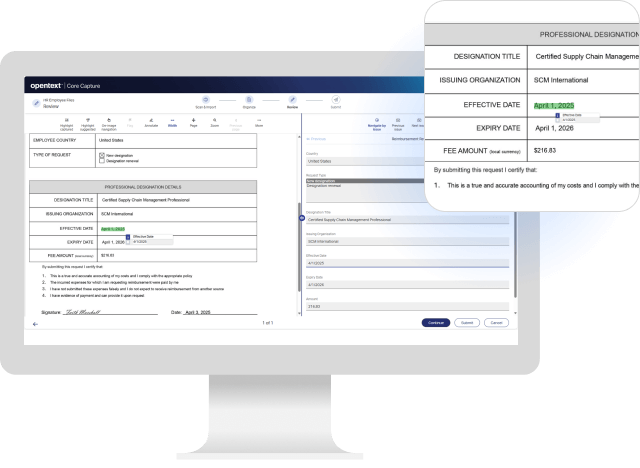
OpenText™ Core Captureは、継続的な機械学習と大規模言語モデル(LLM)を使用して、コンテンツの分類とデータ抽出を自動化するSaaS情報キャプチャソリューションです。光学式文字認識(OCR)などの標準キャプチャ機能と強力なAI技術を組み合わせて、インテリジェントな文書処理ソリューションを可能にし、情報を適切なユーザーやシステムに安全にルーティングします。
OpenText Core Captureが選ばれる理由
シームレスな統合、グローバル展開、信頼できる自動化を活用して、ワークフローを合理化し、複雑さを軽減し、効率を向上させます。
- 統合
緊密な連携に裏打ちされた専用のERPアプリケーションを使用
SAP®ソリューションとの緊密な連携により、ITリソースに負担をかけることなく反復的な会計、販売、サービスタスクを自動化します。
当社の戦略的パートナーの詳細 - グローバルリーチ
国際組織のための柔軟な導入
北米、欧州、アジア太平洋地域のデータレジデンシーオプションを利用して、キャプチャ操作を拡大し、コンプライアンス規制を遵守します。 - 1つのベンダー
エンドツーエンドの文書管理と自動化を提供するIDPへのキャプチャ
統合プロセス自動化、コンテンツサービス、分析を活用してキャプチャを拡張し、複雑さを軽減し、ワークフローを合理化します。
OpenText Content Cloudのご紹介

OpenText Core Content ManagementとOpenText Core Captureを使用することで、ScottsMiracle-GroはAIを活用して文書を要約し、レポートを集約し、データを抽出できるようになり、従業員がイノベーションにより多くの時間を費やせるようになります。
お客様執筆のブログを読む
ユースケース
ドキュメントプロセスを自動化し最適化することで、請求書処理、従業員や顧客のオンボーディング、請求処理、顧客サービス、監査準備に至るまで、ビジネス機能全体の効率、正確性、コンプライアンスを向上させます。
-
調達から支払いまでのプロセスを自動化することで、時間を節約し、価値の高いタスクに集中できます。時間がかかり、エラーが発生しやすい手動の請求書処理に頼る代わりに、電子メール、スキャン、ファックスなどの複数のチャネルから請求書データを簡単に抽出し、検証できます。
発注から支払いまでのプロセス自動化を検討 -
新入社員のプロセスを効率化し、より親しみやすいものにします。クラウドドキュメント処理を使用してファイルを分析および分類し、迅速な検索と人事タスクおよびワークフローの自動化を行います。
人事オートメーションの詳細 -
顧客確認(KYC)および顧客オンボーディングのためのインテリジェントドキュメント処理ソリューションを使用して、データのキャプチャと検証を自動化します。自動化されたCRMワークフローにデータを自動的に取り込み、分類し、抽出することで、営業担当者の時間を削減できます。
顧客オンボーディングを最適化する方法を学ぶ -
請求フォームや文書から実用的なデータを自動的に取得することで、請求処理を強化します。クラウドドキュメント処理は、顧客とスタッフを維持しつつコストを削減し、全体的な効率と満足度を向上させるのに役立ちます。
請求処理を加速する方法を発見 -
時間がかかり、エラーの発生しやすい手作業によるワークフローを削減し、膨大な量のドキュメントに対応することで、顧客サービスとサポートを向上させます。クラウドキャプチャとインテリジェントドキュメント処理で自動化を実現することで、アクション可能なデータで顧客との対話を強化できます。
カスタマーサービスを向上させる方法を見る -
情報キャプチャソリューションを使用してファイルを自動的に分類し、テキスト検索可能なドキュメントに変換することで、検索やアーカイブが容易になり、規制コンプライアンスプログラムのサポートが向上します。
コンプライアンスを確保し、報告を簡素化
主な機能
クラウドキャプチャを一元化し、インテリジェントな文書処理を可能にし、多言語運用をサポートします。自動アップグレード、ヒューマン・イン・ザ・ループ検証、安全なデータ処理により、パフォーマンスを最適化し、手作業を減らすことができます。

マルチテナント型SaaS
完全にメンテナンスされたOpenTextパブリッククラウドにより、複雑なインストールや中断を伴う更新が不要になり、導入の簡素化とアップグレードの自動化によりITの負担が軽減されます。


ヒューマン・イン・ザ・ループ検証
継続的学習エンジンにデータを供給するWeb UIにより精度が向上し、メンテナンスが効率化されると同時に、最適化されたワークフローと使いやすいインターフェースにより生産性が向上します。

マルチモーダル取り込み
紙、メール、PDF、Microsoft®ファイル、画像から自動的に情報を抽出し、部署や拠点を超えたデータ収集を統合し、スケーラブルなコンテンツ管理と共有サービスを実現します。

インテリジェントな文書分類
テキストとグラフィックの方法を使用してドキュメントを識別し、より高い精度とより高速なパフォーマンスを自動的に提供します。

インテリジェントなデータ抽出と検証
組み込みのOCR、機械学習、サードパーティのLLM・認識統合により、手動データ入力を削減し、85の言語とロケールにわたって正確性を確保します。

設定可能なキャプチャワークフロー
ビジネス要件を満たすワークフローを設計することができます。レビュアーの追加やバックグラウンド処理の許可など、シンプルなノーコードモデラーを使用してワークフローテンプレートを作成します。

複数のエクスポートオプション
OpenText™ Core Content Management、OpenText™ Content Management、OpenText™ Documentum™ Content Management、OpenText™ Captureなどの複数のアプリケーションとデータを共有し、CMISを介してソリューションを提供します。
OpenText Core Captureの価値を高める
Add-ons
これらの強力なアドオンにより、OpenText Core Captureへの投資を最大限に活用できます。
-
OpenText™ Core Capture for SAP® Solutions
このSaaS情報キャプチャソリューションにより、OpenText™ Vendor Invoice Management for SAP® Solutionsは、コンテンツを分類し、SAPの適切なワークフローとユーザーへの例外転記とルーティングに必要なすべての詳細を抽出することで、SAPでの受注から支払いまでのプロセスと調達から支払いまでのプロセスを自動化します。
導入
あらゆる規模のグローバル組織に対応するスケーラブルで柔軟な導入オプションを探る
-
選択したクラウドでビジネス情報を保護、拡張、利用
パブリッククラウド
-
情報管理能力の開発、連携、拡張
OpenText Developer CloudからのAPI
サービス内容
認定エキスパートの指導のもとで、デジタル変革を加速します。
-
認定専門家と連携して情報管理を近代化
プロフェッショナルサービス
-
サポートを戦略的優位性に変える
サポートサービス
-
専門家のガイダンス、マネージド サービスなどを活用してビジネス目標を達成
カスタマーサクセスサービス
-
専門的なITサービス管理で社内チームの負担を軽減
Managed Services
パートナー
OpenTextは、お客様が適切なソリューションやサポート、そして期待通りの結果を得られるよう支援します。
エンタープライズアプリケーションパートナー
主要エンタープライズアプリケーションプロバイダーとのパートナーシップにより、企業情報の可能性を最大限に引き出すことができます。
グローバルシステムインテグレーター(GSI)
これらのGSIはOpenTextソリューションのトレーニングと認定を受けており、スタンドアロンソリューションの価値を高めるサービスを提供しています。
トレーニング
OpenTextのラーニングサービス は、知識とスキルを加速させるための包括的なイネーブルメントと学習プログラムを提供します。
-
3-8210 – OpenText Core Captureビジネス管理
このコースでは、詳細な知識とアプリケーションの使用法を含む、実装と管理の基礎を学びます。製品概要、プロセス仕様、設計、システムおよびテナント管理、ユーザー管理、バッチ処理、レポートおよびモニタリングが含まれます。
コミュニティ
OpenTextのコミュニティをご利用ください。 個人や企業とつながり、インサイトやサポートを得ることができます。 ディスカッションに参加する。
-
OpenText Core Captureを使用する従業員、顧客、パートナーのコミュニティが質問をしたり、専門知識を共有したりするためのオープンディスカッションフォーラム
OpenText Core Capture
-
ユーザーと管理者が質問をしたり、専門知識を共有したりするためのオープンディスカッションフォーラム
OpenText Core Capture for SAP Solutions
プレミアムサポート
複雑なIT環境に対応したミッションクリティカルなサポートを提供する専任の専門家が、OpenTextのソリューションの価値を最適化します。
-
技術および戦略的専門家による1対1の個別支援
プレミアムサポート
OpenText Core Capture resources
OpenText Core Capture
Read the product overviewIntelligent document processing
Read the solution overviewContinuous machine learning: Your AI edge
Read the white paperOpenText Cloud Platform (OCP) fundamentals
Read the white paper3 ways to elevate cloud content management
Learn moreIntelligent document processing
Read the solution overviewContinuous machine learning: Your AI edge
Read the white paperOpenText Cloud Platform (OCP) fundamentals
Read the white paper3 ways to elevate cloud content management
Learn moreTransform paper and digital content into actionable data with OpenText Core Capture
Watch the video
ScottsMiracle-Gro saved costs and improved compliance with OpenText
Watch the videoCapture and intelligently file HR documentation for easy onboarding
Watch the demoCapture a batch of documents and then export to OpenText Core Content for further collaboration
Watch the demoOpenText Core Capture and intelligent document processing
Watch the demoCapture a batch of documents and then export to OpenText Core Content for further collaboration
Watch the demoOpenText Core Capture and intelligent document processing
Watch the demoBoost efficiency with SaaS: Future-proof operations with AI-powered cloud content management
Watch the webinarOpenText Content Cloud Virtual Summit 2025
Watch the webinarOpenText Content Cloud Virtual Summit 2025
Watch the webinar-
Cloud capture is the use of cloud-native technology to ingest, classify, and extract data from documents and digital content at scale. As a core component of cloud document processing, it enables organizations to capture content from scanners, email, desktops, and mobile devices while applying AI-based classification and metadata extraction. Cloud capture improves access, resilience, and speed while reducing infrastructure overhead and supporting modern information capture solutions. This enhances efficiency and accessibility by allowing users to process, review, and validate content from anywhere.
Learn more in the OpenText Core Capture product overview.
-
Cloud document processing automates time consuming capture tasks such as document sorting, classification, and data entry. By reducing manual handling and errors, organizations process documents faster and with greater accuracy. The resulting classified content, with actionable metadata, flows easily into business applications, enabling broader intelligent document processing solutions and more efficient end to end workflows.
Discover what intelligent document processing is—and how it relates to cloud data capture.
-
Yes. To help deliver intelligent document processing, OpenText Core Capture seamlessly integrates with ERPs and line-of-business applications, such as SAP® software, to streamline workflows and enhance productivity. These integrations ensure documents and captured data flow directly into business systems without manual handoffs—reducing data entry, improving consistency, and enabling faster, more reliable business processes.
Learn how OpenText Core Capture integrates with SAP® solutions.
-
AI enhances cloud capture by using continuous machine learning, natural language processing, natural language understanding, and large language models (LLM) to automatically classify, extract, and analyze data from content. This improves accuracy and efficiency, allowing organizations to process large volumes of files quickly and reliably. AI-driven capture reduces manual review and exceptions, helping teams scale operations without increasing staff or slowing down the business.
-
Cloud capture processes a wide range of content, including scanned paper, PDFs, emails, office documents, and mobile images. Intelligent document capture applies AI to normalize formats, extract text, and classify documents consistently. This ensures all inbound content is captured the same way, giving organizations a complete and reliable view of their information from the start.
Explore how cloud capture supports intelligent document workflows.
-
Cloud capture enables users to submit and process documents securely from anywhere using browser-based access. By removing dependence on on premises systems, cloud document processing ensures consistent capture quality regardless of location. This helps organizations maintain productivity, service levels, and business continuity across distributed teams.
Review the benefits of cloud-based capture in the OpenText Core Capture product overview.
-
Cloud capture is the first step in automation, converting documents into structured, trustworthy data. Accurate intelligent document capture reduces exceptions and rework downstream, enabling faster approvals and more predictable outcomes. This makes capture a critical foundation for intelligent document processing solutions and scalable business automation.
Discover how cloud capture accelerates OpenText intelligent processing solutions.

OpenText named a Leader in IDC MarketScape for Intelligent Document Processing
Learn why IDC named OpenText a Leader and download the report excerpt.
Read the blogThe new IDP for HR: A springboard for transformation
Discover how to unlock operational efficiency for employee onboarding and more.
Read the blog
What’s new in OpenText Core Capture
See product release highlights for SaaS information capture apps, including SAP and Salesforce.
Read the blog
Supercharge claims processing with an AI content assistant and IDP
See how you can help insurance adjusters resolve claims quickly and improve customer satisfaction.
Read the blog
Elevate customer service with intelligent document processing
Learn how to transform how your organization handles customer interactions and manages information.
Read the blogTransform customer onboarding with intelligent document processing solutions
See why financial institutions need to make processes faster and more accurate.
Read the blog
The ScottsMiracle-Gro Company realizes cost savings by switching to SaaS
See how they streamlined document management with cloud capture and content management.
Read the blog
Streamline procure-to-pay with intelligent document processing solutions
Harness the power of AI to enhance efficiency, reduce errors, and improve supplier relationships.
Read the blog
Ultimate guide to intelligent document processing use cases
Learn how to transform your operations with intelligent document processing solutions use cases.
Read the blog
OpenText named a leader in the 2024 Infosource Global Capture and IDP Vendor Matrix
Learn why Infosource ranked OpenText as a Star for the seventh consecutive year.
Read the blog
Continuous machine learning: Keep up with the digital document deluge
See why organizations are using CML for content classification and data extraction to enable IDP.
Read the blog